
Unlock the power of big data and machine learning with AccentFuture’s Databricks training, designed to help you master the leading unified analytics platform. Our expert-led Databricks courses offer hands-on experience with real-world projects, enabling you to streamline workflows and optimize data-driven solutions. With flexible Databricks online training, you can enhance your skills at your own pace and take a significant step toward a thriving career in data engineering and analytics.
https://github.com/AccentFuture-dev/Databricks/tree/Main/Mastering_Medallion_Architecture_databricks_workshop?source=post_page—–12df1b2dcd6d——————————–
Workshop Agenda
- Introduction to Data Pipelines
- Key Technologies Overview
- Real-Time Data Pipeline Architecture
- Medallion Architecture: Key Concepts
- Hands-On Session: Building the Pipeline
- Real-World Use Case
- Best Practices and Optimization Tips
- Q&A and Wrap-Up
Introduction to Medallion Architecture
The Medallion Architecture is a powerful framework for designing scalable, reliable, and high-performance data pipelines. Popularized by Databricks, this architecture organizes data into three distinct layers: Bronze, Silver, and Gold. Each layer serves a unique purpose in the data lifecycle, from raw data ingestion to refined, analytics-ready datasets. By leveraging Delta Lake as its foundation, the Medallion Architecture ensures data quality, consistency, and efficient querying at scale.
This workshop explores how to implement this architecture step-by-step, providing hands-on experience with tools like Databricks and Azure Data Lake Storage. Whether you’re processing real-time streaming data or building pipelines for machine learning, the Medallion Architecture offers a structured and practical approach to modern data engineering.
Key Technologies Overview
- Databricks:
- A unified analytics platform that simplifies large-scale data processing.
- Supports structured, semi-structured, and unstructured data processing.
2. Delta Lake:
- An open-source storage layer that brings ACID transactions, schema enforcement, and performance optimizations to data lakes.
3. Azure Data Lake Storage (ADLS):
- A scalable cloud storage solution for big data analytics.
- Provides secure and cost-effective storage for Bronze, Silver, and Gold layers.
Real-Time Data Pipeline Architecture
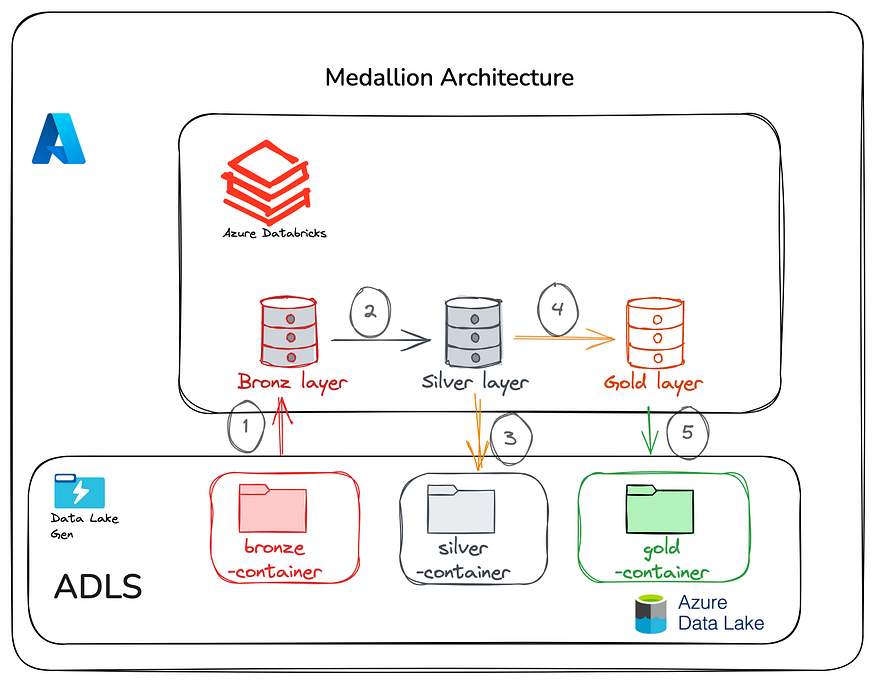
The Medallion Architecture organizes data into three layers:
- Bronze Layer:
- Raw, unprocessed data ingested from various sources.
- Stored in its original format for traceability and future reprocessing.
2. Silver Layer:
- Cleaned and enriched data with applied transformations.
- Includes filtering, deduplication, and validation.
3. Gold Layer:
- Aggregated and optimized datasets ready for analytics and machine learning.

Medallion Architecture: Key Concepts
- Delta Lake Features:
- ACID Transactions: Ensure reliable updates and inserts.
- Schema Enforcement: Prevents schema mismatches.
- Time Travel: Allows querying historical data.
2. Data Transformation Steps:
- Ingesting raw data into the Bronze layer.
- Cleaning and structuring data in the Silver layer.
- Aggregating and optimizing data in the Gold layer.
Hands-On Session: Building the Pipeline
Databricks/Mastering_Medallion_Architecture_databricks_workshop at Main ·…
Contribute to AccentFuture-dev/Databricks development by creating an account on GitHub.
github.com
Step 1: Set Up the Environment
- Configure your Databricks workspace.
- Connect Azure Data Lake Storage (ADLS) to Databricks using a Service Principal.
- Mount All Containers
configs = {
"fs.azure.account.key.developmentrawdata.blob.core.windows.net": "SDQUMP+Wx7k6VFVL6vLp+dVRIjGLSUjEXHjg=="
}
dbutils.fs.mount(
source="wasbs://bronze-container@developmentrawdata.blob.core.windows.net/",
mount_point="/mnt/bronze",
extra_configs=configs
)
dbutils.fs.mount(
source="wasbs://silver-container@developmentrawdata.blob.core.windows.net/",
mount_point="/mnt/silver",
extra_configs=configs
)
dbutils.fs.mount(
source="wasbs://gold-container@developmentrawdata.blob.core.windows.net/",
mount_point="/mnt/gold",
extra_configs=configs
)
###### Verify Mount locations
dbutils.fs.ls("/mnt/")
Step 2: Ingest Raw Data (Bronze Layer)
- Load raw data into the Bronze layer.
- Save the data as a Delta table for further processing.
# Load raw data from Bronze
bronze_path = "/mnt/bronze/sample_1k_data.csv"
bronze_df = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load(bronze_path)
# Write to Delta Lake
bronze_table_path = "/mnt/bronze/delta/"
bronze_df.write.format("delta").mode("overwrite").save(bronze_table_path)
spark.sql(f"CREATE TABLE IF NOT EXISTS bronze_table USING DELTA LOCATION '{bronze_table_path}'")
Step 3: Cleanse and Transform Data (Silver Layer)
- Apply data cleansing and transformation.
- Save the transformed data in the Silver layer.
from pyspark.sql.functions import to_timestamp, col
# Load data from Bronze layer
bronze_df = spark.read.format("delta").load(bronze_table_path)
# Data cleansing and transformation
silver_df = bronze_df.filter(col("event").isNotNull())
.withColumn("event_time", to_timestamp("timestamp", "yyyy-MM-dd HH:mm:ss"))
.drop("timestamp")
# Write to Delta Lake
silver_table_path = "/mnt/silver/delta/"
silver_df.write.format("delta").mode("overwrite").save(silver_table_path)
spark.sql(f"CREATE TABLE IF NOT EXISTS silver_table USING DELTA LOCATION '{silver_table_path}'")
Step 4: Aggregate and Optimize Data (Gold Layer)
- Aggregate data for analytics.
- Save the aggregated data in the Gold layer.
from pyspark.sql.functions import count
# Load data from Silver layer
silver_df = spark.read.format("delta").load(silver_table_path)
# Aggregate data
gold_df = silver_df.groupBy("event").agg(count("user_id").alias("event_count"))
# Write to Delta Lake
gold_table_path = "/mnt/gold/delta/"
gold_df.write.format("delta").mode("overwrite").save(gold_table_path)
spark.sql(f"CREATE TABLE IF NOT EXISTS gold_table USING DELTA LOCATION '{gold_table_path}'")
Real-World Use Case
- Implement a pipeline to analyze user behavior data:
- Track events like logins, purchases, and views.
- Generate insights for personalized recommendations or trend analysis.
Best Practices and Optimization Tips
- Partitioning: Use partitioning for efficient querying.
- Z-Ordering: Optimize file storage for frequently queried columns.
- Caching: Cache intermediate results for iterative processing.
- Data Quality: Implement tools like Great Expectations for validation.
- Scalability: Use cluster autoscaling in Databricks.
Q&A Session
The workshop concluded with a lively Q&A session, where participants asked questions about real-world applications, integration challenges, and specific use cases related to their industries. Attendees were encouraged to share their own experiences and strategies to tackle their unique data pipeline needs.
Conclusion
Building scalable data pipelines using the Medallion Architecture is crucial for industries aiming to leverage real-time data insights. This workshop empowered participants to design their own pipelines by mastering tools like Databricks, Delta Lake, and Azure Data Lake Storage. By implementing the Bronze, Silver, and Gold layers, attendees can ensure data quality, scalability, and efficiency in their workflows.
This hands-on workshop was a valuable opportunity for data engineers and professionals to refine their skills and learn best practices for creating efficient, reliable pipelines. Stay tuned for future workshops to continue your journey in mastering data engineering and pipeline optimization.
Should you encounter any issues, our team is readily available to provide guidance and support with a prompt response. Please do not hesitate to reach out to us at any time contact@accentfuture.com
Wishing you continued success in your coding endeavors  .
.
Transform your data expertise with AccentFuture’s Databricks online training, crafted to equip you with the skills to master big data and machine learning on the leading analytics platform. Gain hands-on experience and elevate your career with our expert-led training.
For more details, visit www.accentfuture.com, call or WhatsApp +91-96400 01789, or email us at contact@accentfuture.com today!

