
Workshop Agenda
- Introduction
- Common Challenges in Data Engineering
- The Solution
- How This Solution Helps
- Architecture Overview
- Step-by-Step Guide to Building the Data Pipeline
- Conclusion
1.Introduction
In today’s data-driven world, managing and processing ever-growing volumes of data efficiently is a critical challenge for organizations. A seamless, scalable, and robust pipeline is essential for ingesting, processing, and storing data to power advanced analytics and decision-making.
This article outlines a comprehensive Proof of Concept (POC) for building an end-to-end data pipeline using Azure Data Lake Storage (ADLS), Databricks, and Snowflake. By the end of this guide, you’ll learn:
- The benefits of a unified data pipeline.
- How to centralize data storage with Azure Data Lake Storage (ADLS).
- Techniques for data processing and transformation with Databricks.
- Leveraging Snowflake for high-performance analytics and querying.
- Steps to build a scalable and production-ready data pipeline for real-world decision-making.
2.Common Challenges in Data Engineering
Organizations often face these challenges when dealing with data:
- Data Silos: Fragmented data across different systems and formats, complicating integration.
- Complex Transformations: Legacy systems struggle with processing structured, semi-structured, and unstructured data.
- Scalability Issues: Traditional pipelines cannot handle increasing data volume and velocity.
- Inconsistent Data Delivery: Delays in ingestion and analytics hinder real-time decision-making.
3.The Solution
This POC demonstrates how to address these challenges by:
1. Centralizing Storage with Azure Data Lake Storage (ADLS):
- Store raw data of all types in a highly scalable and cost-efficient manner.
- Provide centralized access to structured, semi-structured, and unstructured data.
2. Processing and Transforming Data with Databricks:
- Use Databricks’ Apache Spark-based platform for fast, scalable data transformation.
- Simplify complex processing tasks with PySpark and SQL capabilities.
3. Optimizing Analytics with Snowflake:
- Leverage Snowflake’s cloud-native data warehouse for high-performance querying.
- Seamlessly load and access processed data for faster insights and reduced time-to-market.
4.How This Solution Helps
- Efficiency: Automates the entire data pipeline, minimizing manual interventions and errors.
- Scalability: Handles increasing data volumes and complex workflows with ease.
- Real-Time Analytics: Ensures timely data delivery for accurate decision-making.
- Future-Ready: Lays the foundation for advanced use cases such as machine learning and real-time analytics.

This solution is designed for professionals seeking expertise in data engineering. With training on platforms like Azure, Databricks, and Snowflake, individuals can master modern tools to overcome today’s data challenges.
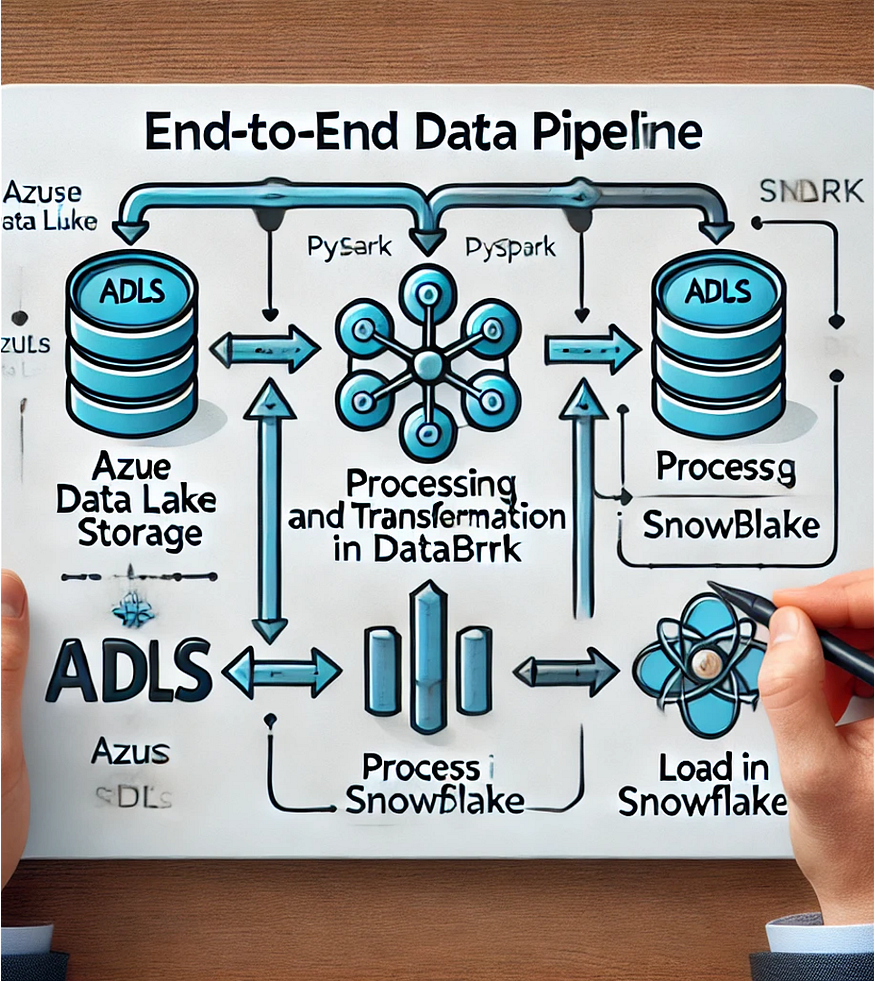
5.Architecture Overview
The architecture integrates the following components:
- Data Ingestion: Raw data is ingested into ADLS.
- Data Processing: Databricks processes and transforms the data.
- Data Storage and Analytics: Snowflake stores the processed data and enables high-performance analytics.
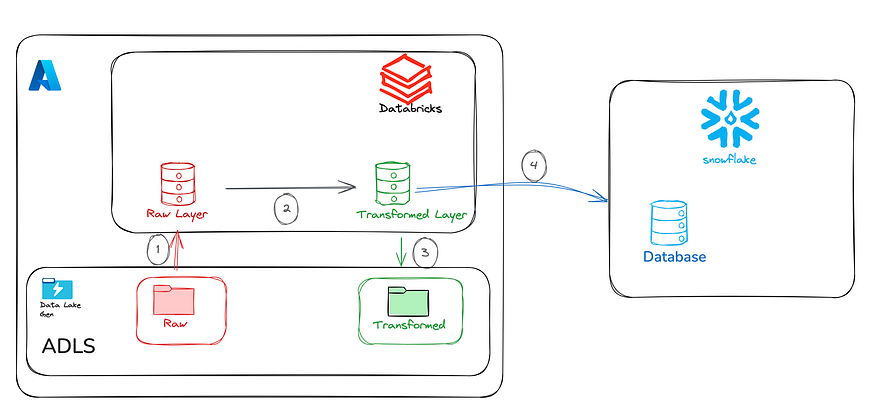
6.Step-by-Step Guide to Building the Data Pipeline
Step 1: Setting up Azure Data Lake Storage (ADLS)
- Create an Azure Storage Account: Set up a storage account to host your data lake.
- Enable Hierarchical Namespace: Optimize for big data workloads.
- Organize Data: Structure your data into raw, processed, and curated zones for better management.


Step 2: Processing Data in Databricks
- Set Up Databricks Workspace: Create a workspace on Azure Databricks.
- Configure Cluster: Choose a Spark cluster suited to your data volume and workload.
- Ingest Data: Use Databricks to connect to ADLS and read raw data.
- Transform Data: Write PySpark or SQL scripts for data cleansing and transformation.
- Store Processed Data: Save the processed data back to ADLS in the processed zone.

ADLS-> Databricks -> Transformed->ADLS CODE:
# Mount ADLS to Databricks
configs = {
"fs.azure.account.key.developmentrawdata.blob.core.windows.net":
"UWXic3OBQFiR3QSl2tDzG8tXleE4N3p0Ug2313fsqfasfqfqerqe311ZNA=="
}
dbutils.fs.mount(
source="wasbs://raw@developmentrawdata.blob.core.windows.net/",
mount_point="/mnt/raw_data",
extra_configs=configs
)
# Verify Mount location
dbutils.fs.ls("/mnt/raw_data")
# Read data from databricks mounted location to spark data frame
raw_data = spark.read.csv("/mnt/raw_data/raw_data.csv", header=True,
inferSchema=True)
raw_data.show()
# Transform data
transformed_data = raw_data.filter(raw_data['age'] > 18)
.withColumnRenamed("age", "user_age")
transformed_data.show()
# Write transform results into parquet format
transformed_data.write.mode("overwrite").parquet("/mnt/processed_data")
# list of files in processed mount location
dbutils.fs.ls("/mnt/processed_data")Step 3: Loading Data into Snowflake
- Install Snowflake Spark Connector in Databricks.
- Configure connection to Snowflake.
- Load processed data from ADLS into Snowflake tables.
- Verify data with SQL queries.
Databricks -> Snowflake Code
# MAGIC %pip install snowflake-connector-python
# MAGIC %pip install snowflake-sqlalchemy
# MAGIC
# COMMAND ----------
snowflake_options = {
"sfURL": "https://jaqhoasasnw-wt95891.snowflakecomputing.com",
"sfDatabase": "Transformed_DB",
"sfSchema": "PUBLIC",
"sfWarehouse": "COMPUTE_WH",
"sfRole": "ACCOUNTADMIN",
"sfUser": "ACCENTFUTURE",
"sfPassword": "************"
}
# COMMAND ----------
transformed_data.write \
.format("snowflake") \
.options(**snowflake_options) \
.option("dbtable", "processed_data_table") \
.mode("overwrite") \
.save()
# COMMAND ----------
transformed_data.write.format("delta").mode("overwrite")
.save("/mnt/delta/processed_data")
# COMMAND ----------
dbutils.fs.ls("/mnt/delta/processed_data")
7.Conclusion:
Congratulations! You’ve successfully built an end-to-end data pipeline integrating Azure Data Lake Storage, Databricks, and Snowflake. This scalable and efficient pipeline showcases the power of modern data platforms. Leveraging this approach ensures reliable data processing and analytics, making it ideal for professionals aspiring to master data engineering with AccentFuture Training.
By following these steps, you’ve unlocked the potential to handle real-world data engineering challenges and build production-ready pipelines. Let’s build the future of data workflows together!
This hands-on workshop was an excellent opportunity for data engineers and professionals to hone their skills and learn how to create efficient, scalable real-time pipelines. Stay tuned for future workshops to continue mastering the world of data engineering!
Should you encounter any issues, our team is readily available to provide guidance and support with a prompt response. Please do not hesitate to reach out to us at any time contact@accentfuture.com
Wishing you continued success in your coding endeavors  .
.


